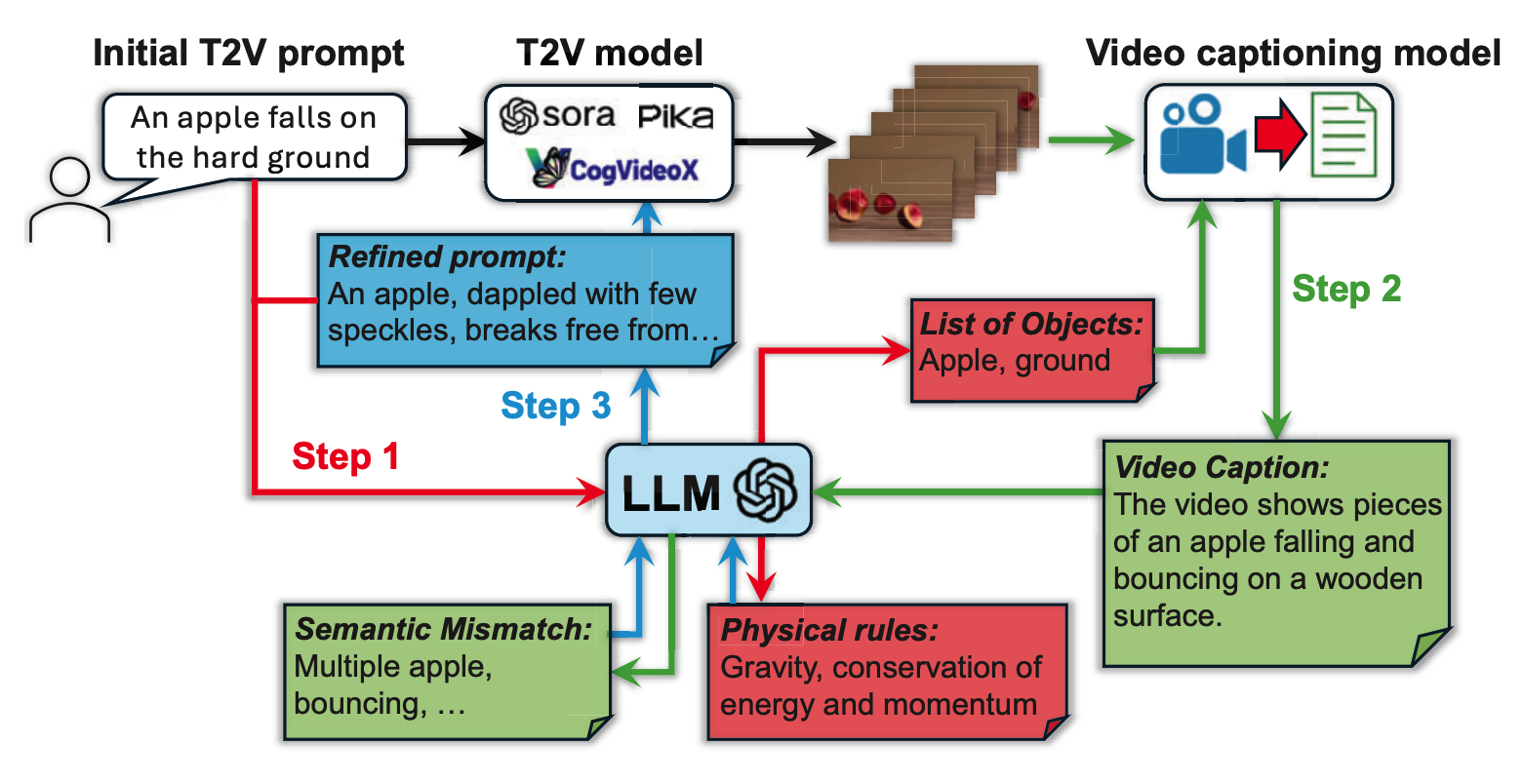
@inproceedings{xue2025phyt2v,title={Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video generation},author={Xue, Qiyao and Yin, Xiangyu and Yang, Boyuan and Gao, Wei},booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},pages={18826--18836},year={2025},doi={10.48550/arXiv.2412.00596},publisher={CVPR},selected=true}
@inproceedings{yin2025progait,title={ProGait: A Multi-Purpose Video Dataset and Benchmark for Transfemoral Prosthesis Users},author={Yin, Xiangyu and Yang, Boyuan and Liu, Weichen and Xue, Qiyao and Alamri, Abrar and Fiedler, Goeran and Gao, Wei},booktitle={Proceedings of the International Conference on Computer Vision},year={2025},doi={10.48550/arXiv.2507.10223},publisher={ICCV},selected=true}
Arxiv
MMBERT: Scaled Mixture-of-Experts Multimodal BERT for Robust Chinese Hate Speech Detection under Cloaking Perturbations
Qiyao Xue, Yuchen Dou, Ryan Shi, and 2 more authors
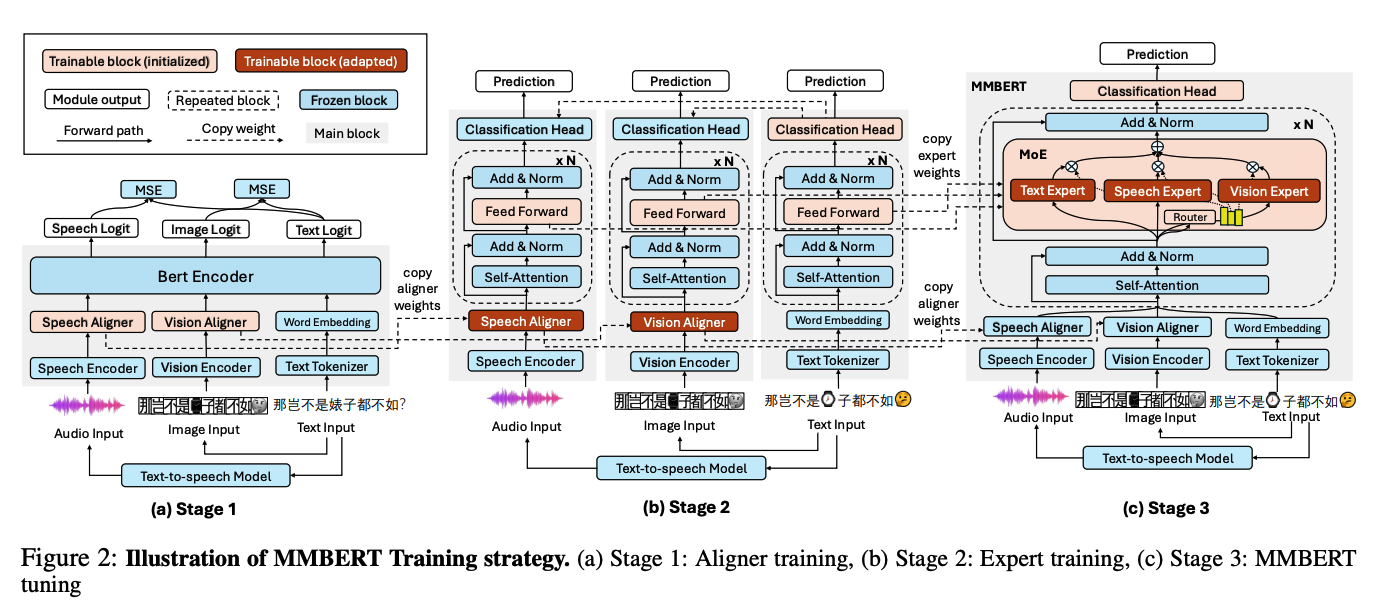
@journal{xue2025mmbertscaledmixtureofexpertsmultimodal,title={MMBERT: Scaled Mixture-of-Experts Multimodal BERT for Robust Chinese Hate Speech Detection under Cloaking Perturbations},author={Xue, Qiyao and Dou, Yuchen and Shi, Ryan and Li, Xiang Lorraine and Gao, Wei},booktitle={arXiv},year={2025},doi={10.48550/arXiv.2508.00760},publisher={arXiv}}